If you have ever tried to extract a table from a PDF invoice, you know the frustration. You select the rows, paste into Excel, and the result is a single column of concatenated text. Cell boundaries vanish. Numbers merge with labels. Multi-page tables split at random page breaks. Subtotals and tax lines end up scattered across the wrong rows.
Traditional approaches fall into two camps: OCR-based services that re-read the document as an image (slow, often inaccurate, and require uploading your files to a third-party server), or manual copy-paste followed by 30 minutes of cleanup in Excel. Neither is acceptable when you are processing invoices on a deadline.
PDFTable Extractor takes a different approach entirely. It parses the native text layer of your PDF directly in the browser using pdf.js, identifies table boundaries through column alignment analysis, separates distinct table structures, and lets you review every row before export. No OCR engine. No server-side processing. No account required.
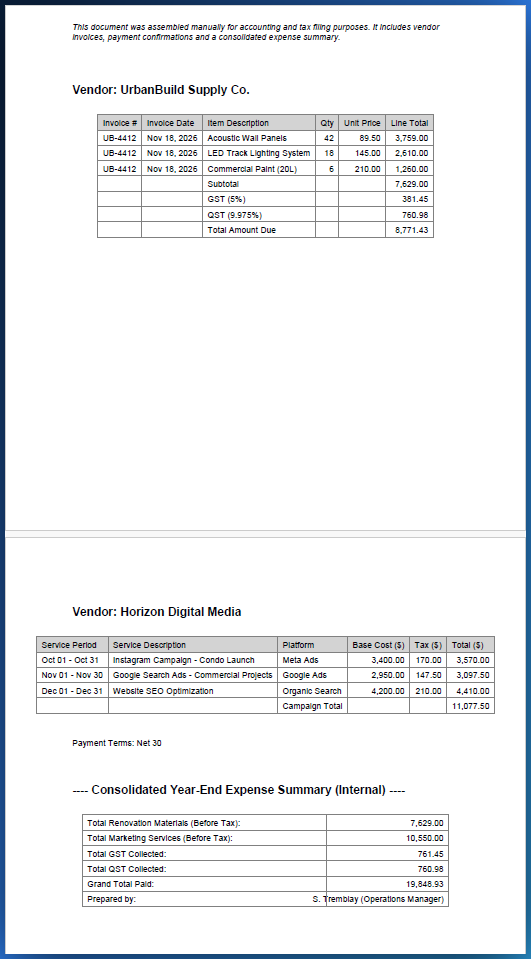
In this walkthrough, we will process a real two-page supplier invoice containing three distinct table structures: a line-item table spanning both pages, a date/reference table, and an invoice summary with subtotals, GST, QST, and a signature row. The entire workflow takes under 30 seconds.
Si vous avez déjà essayé d'extraire un tableau d'une facture PDF, vous connaissez la frustration. Vous sélectionnez les lignes, collez dans Excel, et le résultat est une seule colonne de texte concaténé. Les limites de cellules disparaissent. Les chiffres fusionnent avec les étiquettes. Les tableaux multi-pages se coupent aux sauts de page aléatoires. Les sous-totaux et lignes de taxes se retrouvent éparpillés sur les mauvaises lignes.
Les approches traditionnelles se divisent en deux camps : les services basés sur l'OCR qui relisent le document comme une image (lents, souvent imprécis, et nécessitant le téléchargement de vos fichiers vers un serveur tiers), ou le copier-coller manuel suivi de 30 minutes de nettoyage dans Excel. Aucune de ces options n'est acceptable quand vous traitez des factures sous pression.
PDFTable Extractor adopte une approche complètement différente. Il analyse la couche de texte native de votre PDF directement dans le navigateur via pdf.js, identifie les limites des tableaux par analyse d'alignement de colonnes, sépare les structures de tableaux distinctes, et vous permet de revoir chaque ligne avant l'export. Pas de moteur OCR. Pas de traitement côté serveur. Pas de compte requis.
Dans ce guide, nous allons traiter une vraie facture fournisseur de deux pages contenant trois structures de tableaux distinctes : un tableau de postes couvrant les deux pages, un tableau de dates/références, et un récapitulatif de facture avec sous-totaux, TPS, TVQ et une ligne de signature. Le processus complet prend moins de 30 secondes.
The Source: A Real Multi-Page Invoice
Le document source : une vraie facture multi-pages
Our test document is a two-page supplier invoice. Page one contains the header block (vendor name, address, invoice number) followed by the beginning of a line-item table. Page two continues that same table and adds a totals block with subtotal, GST (5%), QST (9.975%), grand total, and a signature field. There is also a secondary table with date and reference columns that uses a completely different column structure.
Notre document de test est une facture fournisseur de deux pages. La première page contient le bloc d'en-tête (nom du fournisseur, adresse, numéro de facture) suivi du début d'un tableau de postes. La deuxième page continue ce même tableau et ajoute un bloc de totaux avec sous-total, TPS (5 %), TVQ (9,975 %), grand total et un champ de signature. Il y a aussi un tableau secondaire avec des colonnes de date et de référence utilisant une structure de colonnes complètement différente.
This is the kind of document that breaks every generic PDF-to-Excel converter: mixed table structures on the same page, continuation across page boundaries, and metadata rows (tax lines, signatures) interleaved with data rows.
C'est le type de document qui casse tous les convertisseurs génériques PDF vers Excel : des structures de tableaux mixtes sur la même page, une continuation à travers les limites de pages, et des lignes de métadonnées (lignes de taxes, signatures) entrelacées avec les lignes de données.
Step 1: Upload and Automatic Table Detection
Étape 1 : Téléchargement et détection automatique des tableaux
Drop your PDF into PDFTable Extractor (or click to browse). The tool reads the file entirely in your browser using Mozilla's pdf.js library. No bytes leave your machine.
Déposez votre PDF dans PDFTable Extractor (ou cliquez pour parcourir). L'outil lit le fichier entièrement dans votre navigateur en utilisant la bibliothèque pdf.js de Mozilla. Aucun octet ne quitte votre machine.
Within seconds, the extraction engine performs several operations:
En quelques secondes, le moteur d'extraction effectue plusieurs opérations :
- Text layer parsing: Reads every text element from each page with its exact x/y coordinates and font metadata
- Column alignment analysis: Groups text elements by their horizontal position to detect column boundaries
- Row clustering: Identifies which text elements belong to the same logical row based on vertical proximity
- Table boundary detection: Separates distinct table structures by analyzing column count changes and structural breaks
- Row classification: Labels each row as a data row, header row, or summary row (subtotals, taxes, totals) using pattern matching on cell content
- Analyse de la couche texte : Lit chaque élément de texte de chaque page avec ses coordonnées x/y exactes et ses métadonnées de police
- Analyse d'alignement des colonnes : Regroupe les éléments de texte par leur position horizontale pour détecter les limites de colonnes
- Regroupement des lignes : Identifie quels éléments de texte appartiennent à la même ligne logique en se basant sur la proximité verticale
- Détection des limites de tableaux : Sépare les structures de tableaux distinctes en analysant les changements de nombre de colonnes et les ruptures structurelles
- Classification des lignes : Étiquette chaque ligne comme ligne de données, ligne d'en-tête ou ligne de récapitulatif (sous-totaux, taxes, totaux) par correspondance de motifs sur le contenu des cellules
For our two-page invoice, the engine detected three separate tables with different column structures. Each is presented in its own tab, ready for individual review and export.
Pour notre facture de deux pages, le moteur a détecté trois tableaux distincts avec des structures de colonnes différentes. Chacun est présenté dans son propre onglet, prêt pour revue individuelle et export.
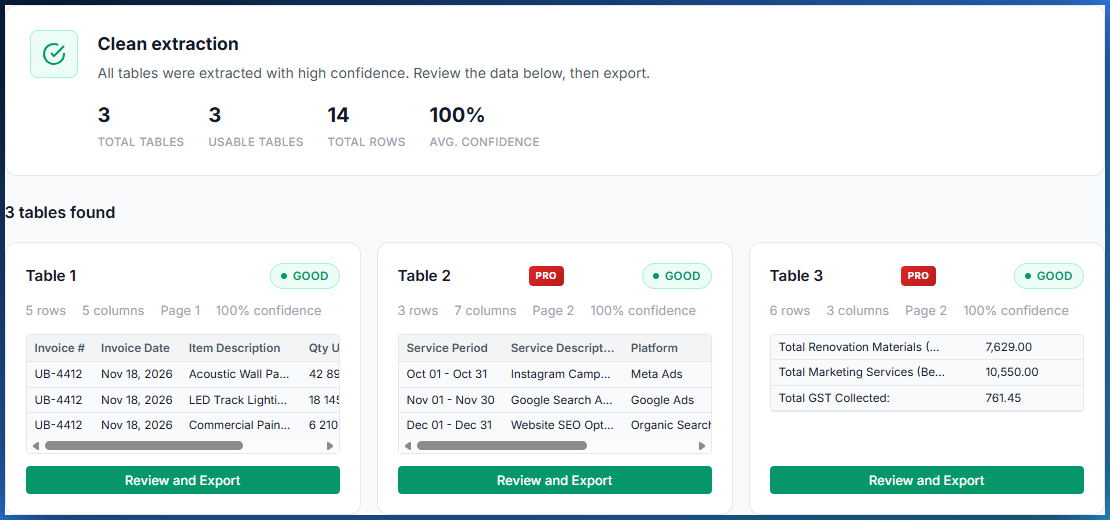
PDFTable does not rely on visible gridlines or cell borders (many invoices have none). Instead, it analyzes the horizontal alignment of text elements across rows. When a group of consecutive rows share the same set of column positions, they belong to the same table. When the column pattern changes significantly (different number of columns, different x-offsets), the engine inserts a table break. This is what allows it to separate a 5-column line-item table from a 2-column date table on the same page.
PDFTable ne se fie pas aux lignes de quadrillage visibles ou aux bordures de cellules (beaucoup de factures n'en ont pas). Il analyse plutôt l'alignement horizontal des éléments de texte à travers les lignes. Quand un groupe de lignes consécutives partagent le même ensemble de positions de colonnes, elles appartiennent au même tableau. Quand le motif de colonnes change significativement (nombre de colonnes différent, décalages x différents), le moteur insère une rupture de tableau. C'est ce qui lui permet de séparer un tableau de postes à 5 colonnes d'un tableau de dates à 2 colonnes sur la même page.
Step 2: Row Classification and Manual Override
Étape 2 : Classification des lignes et contrôle manuel
Once the tables are extracted, PDFTable classifies each row into one of two categories:
Une fois les tableaux extraits, PDFTable classifie chaque ligne dans l'une des deux catégories :
- Data rows - Regular line items that belong in the exported table (products, services, individual entries)
- Summary rows - Aggregation lines like subtotals, tax calculations (GST, QST, HST, TVA), grand totals, and metadata (signatures, notes, payment terms)
- Lignes de données - Les postes réguliers qui appartiennent au tableau exporté (produits, services, entrées individuelles)
- Lignes de récapitulatif - Les lignes d'agrégation comme les sous-totaux, calculs de taxes (TPS, TVQ, TVH, TVA), grands totaux et métadonnées (signatures, notes, conditions de paiement)
This classification is performed automatically using pattern matching: the engine scans each row's cell values for keywords like "total", "subtotal", "tax", "GST", "QST", "signature", and numeric patterns consistent with percentage calculations. However, automatic classification is not always perfect. Some rows are ambiguous - a row labeled "Adjustment" might be a legitimate line item or a summary correction.
Cette classification est effectuée automatiquement par correspondance de motifs : le moteur scanne les valeurs de cellules de chaque ligne pour des mots-clés comme « total », « sous-total », « taxe », « TPS », « TVQ », « signature », et des motifs numériques cohérents avec des calculs de pourcentage. Cependant, la classification automatique n'est pas toujours parfaite. Certaines lignes sont ambiguës - une ligne étiquetée « Ajustement » peut être un poste légitime ou une correction de récapitulatif.
This is where the manual override comes in. Every row has a one-click toggle button. If the engine classified a data row as a summary row (or vice versa), you click the button and it switches instantly. The table preview updates in real time, so you can see exactly what your export will contain before downloading.
C'est là qu'intervient le contrôle manuel. Chaque ligne dispose d'un bouton de basculement en un clic. Si le moteur a classifié une ligne de données comme ligne de récapitulatif (ou inversement), vous cliquez sur le bouton et elle bascule instantanément. L'aperçu du tableau se met à jour en temps réel, pour que vous puissiez voir exactement ce que votre export contiendra avant le téléchargement.
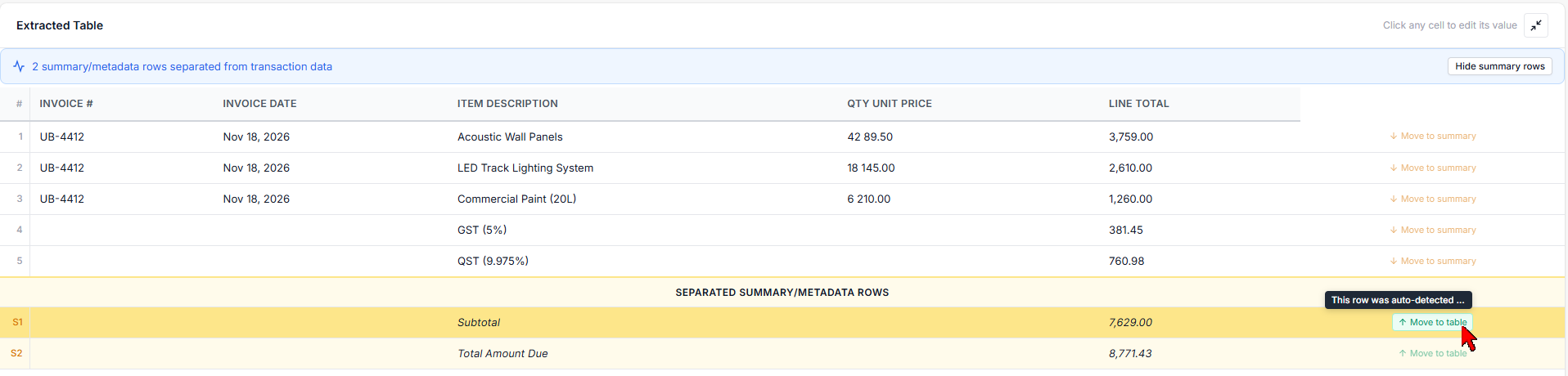
This level of control matters in practice. In our invoice, the engine correctly identified the subtotal, GST (5%), QST (9.975%), and grand total rows as summary lines - they should not appear as regular line items in an accounting import. But if your workflow requires those rows in the export (for example, to reconcile tax amounts), you can include them with a single click.
Ce niveau de contrôle a son importance en pratique. Dans notre facture, le moteur a correctement identifié les lignes de sous-total, TPS (5 %), TVQ (9,975 %) et grand total comme lignes de récapitulatif - elles ne devraient pas apparaître comme postes réguliers dans un import comptable. Mais si votre flux de travail nécessite ces lignes dans l'export (par exemple, pour rapprocher les montants de taxes), vous pouvez les inclure d'un seul clic.
Step 3: Multiple Table Structures, Cleanly Separated
Étape 3 : Structures de tableaux multiples, séparées proprement
One of the most common failures in PDF extraction is table merging. When a PDF contains two tables with different column counts on the same page, most extractors either merge them into one broken table (with misaligned cells) or miss the second table entirely.
L'un des échecs les plus courants dans l'extraction PDF est la fusion de tableaux. Quand un PDF contient deux tableaux avec des nombres de colonnes différents sur la même page, la plupart des extracteurs les fusionnent en un seul tableau cassé (avec des cellules désalignées) ou manquent entièrement le deuxième tableau.
PDFTable handles this correctly. Our invoice has a main line-item table with 5 columns and a secondary date/reference table with 2 columns. The engine detects the column structure shift and creates separate table entities. Each table gets its own tab, its own header row detection, and its own export.
PDFTable gère cela correctement. Notre facture a un tableau principal de postes avec 5 colonnes et un tableau secondaire de dates/références avec 2 colonnes. Le moteur détecte le changement de structure de colonnes et crée des entités de tableaux séparées. Chaque tableau obtient son propre onglet, sa propre détection d'en-tête et son propre export.
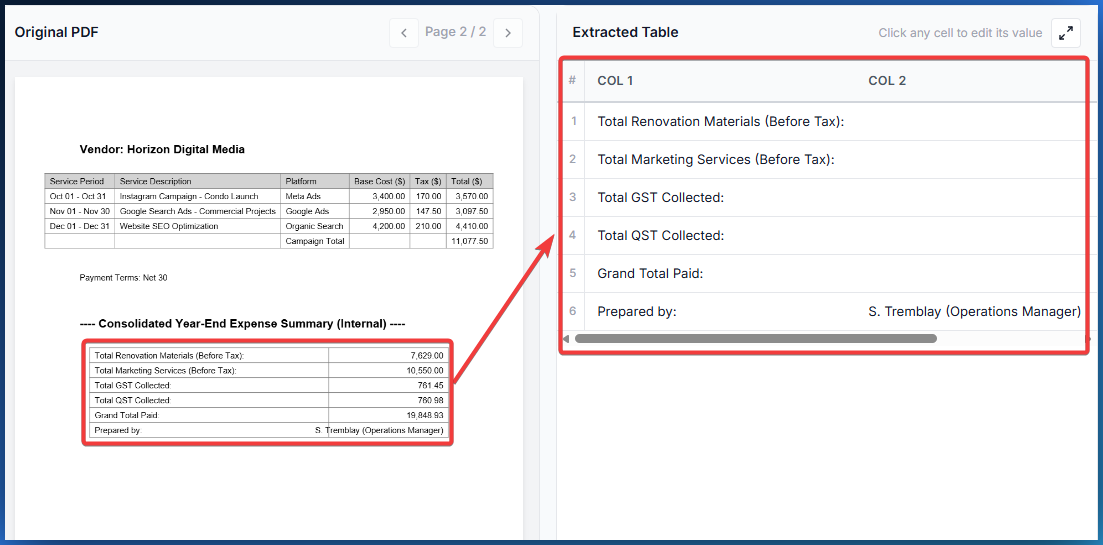
The Invoice Summary Table: Totals, Taxes, and Signatures
Le tableau récapitulatif : totaux, taxes et signatures
The third table detected is the invoice summary block. This typically sits at the bottom of the last page and contains the subtotal, applicable taxes, grand total, and often a signature or approval field. These rows have a distinctive pattern: two columns (a label and an amount), with the label being a keyword like "Subtotal", "GST", "QST", or "Total Due".
Le troisième tableau détecté est le bloc récapitulatif de la facture. Il se situe généralement en bas de la dernière page et contient le sous-total, les taxes applicables, le grand total, et souvent un champ de signature ou d'approbation. Ces lignes ont un motif distinctif : deux colonnes (une étiquette et un montant), avec l'étiquette étant un mot-clé comme « Sous-total », « TPS », « TVQ », ou « Total dû ».
PDFTable recognizes this as a separate table entity and preserves its structure. The subtotal, tax lines, and total row are classified as summary rows by default, but the signature row is also captured. Nothing is lost or discarded - you control what gets included in the final export.
PDFTable reconnaît ceci comme une entité de tableau séparée et préserve sa structure. Le sous-total, les lignes de taxes et la ligne de total sont classifiés comme lignes de récapitulatif par défaut, mais la ligne de signature est aussi capturée. Rien n'est perdu ni rejeté - vous contrôlez ce qui est inclus dans l'export final.
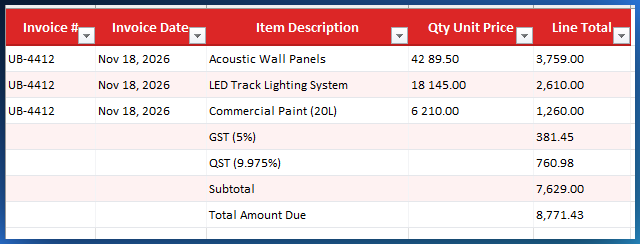
Step 4: Export to Professionally Formatted Excel
Étape 4 : Export vers Excel avec formatage professionnel
Once you have reviewed and adjusted the row classifications, click the Export to Excel button. PDFTable generates a .xlsx file using the xlsx-js-style library (a fork of SheetJS with styling support). The export is not a raw data dump. It produces a properly formatted Excel table with:
Une fois que vous avez revu et ajusté les classifications de lignes, cliquez sur le bouton Exporter vers Excel. PDFTable génère un fichier .xlsx en utilisant la bibliothèque xlsx-js-style (un fork de SheetJS avec support du style). L'export n'est pas un vidage de données brut. Il produit un tableau Excel correctement formaté avec :
- Styled header row: Bold white text on a dark background, clearly distinguishing headers from data
- AutoFilter enabled: Click any column header to sort or filter - the dropdown arrows are already attached
- Banded rows: Alternating row colors (white and light gray) for improved readability on dense tables
- Auto-sized columns: Column widths are calculated from the actual cell content, so nothing gets clipped or excessively padded
- Proper borders: Thin borders on all cells give the table a clean, structured appearance
- Generic headers for headerless tables: If the source PDF table has no detectable header row, PDFTable generates "Column 1", "Column 2", etc. instead of using the first data row as a header (a common bug in other tools)
- Ligne d'en-tête stylisée : Texte blanc gras sur fond sombre, distinguant clairement les en-têtes des données
- Filtre automatique activé : Cliquez sur n'importe quel en-tête de colonne pour trier ou filtrer - les flèches déroulantes sont déjà en place
- Lignes alternées : Alternance de couleurs de lignes (blanc et gris clair) pour une meilleure lisibilité sur les tableaux denses
- Colonnes auto-dimensionnées : Les largeurs de colonnes sont calculées à partir du contenu réel des cellules, donc rien n'est tronqué ni excessivement espacé
- Bordures correctes : Des bordures fines sur toutes les cellules donnent au tableau une apparence propre et structurée
- En-têtes génériques pour les tableaux sans en-tête : Si le tableau PDF source n'a pas de ligne d'en-tête détectable, PDFTable génère « Column 1 », « Column 2 », etc. au lieu d'utiliser la première ligne de données comme en-tête (un bug courant dans les autres outils)
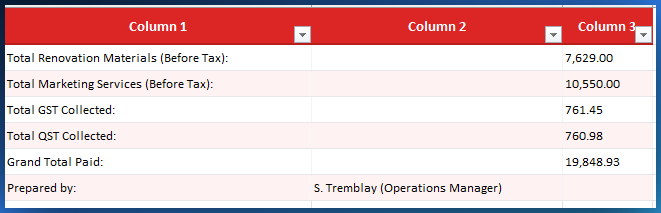
Each table exports independently. You do not get a single sheet with all tables concatenated together. Table 1 exports as its own file, Table 2 as its own file, and so on. This means your line-item table, date table, and summary table each produce a clean, self-contained .xlsx file.
Chaque tableau s'exporte indépendamment. Vous n'obtenez pas une seule feuille avec tous les tableaux concaténés ensemble. Le Tableau 1 s'exporte dans son propre fichier, le Tableau 2 dans le sien, et ainsi de suite. Cela signifie que votre tableau de postes, votre tableau de dates et votre tableau récapitulatif produisent chacun un fichier .xlsx propre et autonome.

Under the Hood: How PDFTable Differs from OCR-Based Extractors
Sous le capot : comment PDFTable se distingue des extracteurs basés sur l'OCR
Most PDF table extraction tools follow one of two architectures:
La plupart des outils d'extraction de tableaux PDF suivent l'une de deux architectures :
| Approach | How it works | Limitations |
|---|---|---|
| OCR-based (Tabula, Camelot, cloud APIs) | Renders the PDF as an image, then uses optical character recognition to detect text positions | Slow, error-prone on complex layouts, requires server-side processing or Python runtime |
| Text-layer parsing (PDFTable) | Reads the native text objects embedded in the PDF with their exact coordinates | Only works on PDFs with embedded text (not scanned images). Faster and more accurate for digital-native documents. |
| Approche | Fonctionnement | Limitations |
|---|---|---|
| Basée sur l'OCR (Tabula, Camelot, API cloud) | Rend le PDF comme une image, puis utilise la reconnaissance optique de caractères pour détecter les positions du texte | Lent, sujet aux erreurs sur les mises en page complexes, nécessite un traitement côté serveur ou un environnement Python |
| Analyse de la couche texte (PDFTable) | Lit les objets texte natifs intégrés dans le PDF avec leurs coordonnées exactes | Fonctionne uniquement sur les PDF avec texte intégré (pas les images scannées). Plus rapide et plus précis pour les documents natifs numériques. |
Because PDFTable works with the native text layer, it has access to exact character positions (to the sub-pixel level), font sizes, and font weights. This means column detection is based on precise coordinate clustering rather than visual approximation, which is why it can separate two tables with different column counts on the same page without merging them.
Puisque PDFTable travaille avec la couche texte native, il a accès aux positions exactes des caractères (au niveau du sous-pixel), aux tailles de police et aux graisses de police. Cela signifie que la détection des colonnes est basée sur un regroupement précis de coordonnées plutôt qu'une approximation visuelle, ce qui explique pourquoi il peut séparer deux tableaux avec des nombres de colonnes différents sur la même page sans les fusionner.
PDFTable runs entirely in JavaScript using Mozilla's pdf.js for PDF parsing and SheetJS for Excel generation. There is no backend server, no API call, no analytics tracking on your file content. Your financial documents stay on your machine at all times. This makes PDFTable compliant with data residency requirements by default - there is nothing to configure because there is nowhere for data to go.
PDFTable fonctionne entièrement en JavaScript en utilisant pdf.js de Mozilla pour l'analyse PDF et SheetJS pour la génération Excel. Il n'y a pas de serveur backend, pas d'appel API, pas de suivi analytique sur le contenu de vos fichiers. Vos documents financiers restent sur votre machine en permanence. Cela rend PDFTable conforme aux exigences de résidence des données par défaut - il n'y a rien à configurer car il n'y a nulle part où les données pourraient aller.
Common Use Cases for PDF Table Extraction
Cas d'utilisation courants pour l'extraction de tableaux PDF
While this walkthrough focused on an accounts payable invoice, PDFTable handles a wide range of tabular PDF documents:
Bien que ce guide se soit concentré sur une facture fournisseur, PDFTable gère une large gamme de documents PDF tabulaires :
- Supplier invoices: Extract line items, quantities, unit prices, and amounts into Excel for import into your accounting system (QuickBooks, Sage, Xero)
- Bank statements: Pull transaction tables from monthly PDF statements for reconciliation
- Government tax reports: Extract assessment tables and remittance schedules from CRA or Revenu Quebec documents
- Insurance schedules: Pull coverage tables and premium breakdowns from policy documents
- Purchase orders: Extract item lists for cross-referencing against receiving reports
- Financial statements: Pull balance sheet and income statement tables from audited PDF reports
- Factures fournisseurs : Extraire les postes, quantités, prix unitaires et montants vers Excel pour import dans votre système comptable (QuickBooks, Sage, Xero)
- Relevés bancaires : Extraire les tableaux de transactions des relevés PDF mensuels pour le rapprochement
- Rapports fiscaux gouvernementaux : Extraire les tableaux d'évaluation et les calendriers de versement des documents de l'ARC ou de Revenu Québec
- Barèmes d'assurance : Extraire les tableaux de couverture et les ventilations de primes des documents de police
- Bons de commande : Extraire les listes d'articles pour le recoupement avec les rapports de réception
- États financiers : Extraire les tableaux de bilan et d'état des résultats des rapports PDF audités
Summary: What We Extracted in Under 30 Seconds
Résumé : ce que nous avons extrait en moins de 30 secondes
Starting from a two-page supplier invoice, PDFTable Extractor performed the following in a single upload:
À partir d'une facture fournisseur de deux pages, PDFTable Extractor a effectué les opérations suivantes en un seul téléchargement :
- Detected 3 separate tables with distinct column structures from a single PDF
- Classified rows automatically into data rows and summary rows (subtotals, taxes, totals, signatures)
- Provided one-click row reclassification for edge cases and ambiguous rows
- Exported each table independently to a professionally formatted .xlsx file with AutoFilter, banded rows, styled headers, and auto-sized columns
- Generated generic column headers for tables without a detectable header row, preventing the first data row from being consumed as headers
- Processed everything locally in the browser with zero server communication
- Détection de 3 tableaux distincts avec des structures de colonnes différentes à partir d'un seul PDF
- Classification automatique des lignes en lignes de données et lignes de récapitulatif (sous-totaux, taxes, totaux, signatures)
- Reclassification en un clic pour les cas limites et les lignes ambiguës
- Export de chaque tableau indépendamment vers un fichier .xlsx formaté professionnellement avec filtre automatique, lignes alternées, en-têtes stylisés et colonnes auto-dimensionnées
- Génération d'en-têtes de colonnes génériques pour les tableaux sans ligne d'en-tête détectable, empêchant la première ligne de données d'être utilisée comme en-têtes
- Traitement entièrement local dans le navigateur avec zéro communication serveur
Try PDFTable Extractor for Free
Upload any PDF with tables. Extract, review, and export to Excel in seconds. No sign-up, no cloud upload, 100% private.
Essayez PDFTable Extractor gratuitement
Téléchargez n'importe quel PDF contenant des tableaux. Extrayez, révisez et exportez vers Excel en quelques secondes. Pas d'inscription, pas de téléchargement cloud, 100 % privé.